

Share
Real-time Video Analytics
Real-time video analytics is a powerful cutting-edge technology that leverages advanced algorithms and computational power to analyze video streams instantaneously. This transformative capability enables systems to extract meaningful insights from live video feeds, making it invaluable across various industries. In the realm of security, real-time video analytics enables detecting threats and dangers instantly, recognizing unusual activities reliably, or identifying potential security breaches promptly. Thorough investigation and prevention of risk factors fosters a prolifically protected environment. In retail sectors, it facilitates customer-behavior analysis, thereby helping businesses understand shopping patterns and optimize store layouts for enhanced customer experiences. Increased customer footfall and exceptional shopping setups are key benefits for proliferating profits. Moreover, in the healthcare sector, real-time video analytics can be employed for patient monitoring, ensuring timely responses to critical situations. The technology relies on sophisticated computer vision (CV), machine learning (ML), and artificial intelligence (AI) techniques to process vast amounts of visual data in real time. Accurate analysis and prudent prognosis of even complicated medical conditions is propelled through cohesive mechanisms. As ingenious advancements continue, real-time video analytics is poised to play an increasingly pivotal role in shaping the future of surveillance, automation, and data-driven decision-making across diverse domains.
Challenges
Real-time video analytics poses several challenges, primarily due to the demanding nature of processing large volumes of visual data within crunched timeframes. Firstly, the predominant challenge is the need for robust and efficient algorithms that can accurately extract relevant information from video streams in real-time. This crucial condition requires resolute AI model optimization techniques, such as pruning, quantization, and Neural Architecture Search (NAS).
Secondly, full-flow processing and AI inferencing in video analysis present intricate technical roadblocks. One notable bottleneck is the need for high computational power to process video frames seamlessly through the entire analysis pipeline. From pre-processing to AI inferencing, and ultimately post-processing, each stage of operation requires swift computation of information to maintain real-time responsiveness. Implementing AI models for object recognition, tracking, and behavior-analysis intensifies the computational load, demanding efficient hardware architectures such as GPUs, NPUs, or specialized accelerators. Furthermore, optimizing these models for realizing low-latency inferencing is paramount, as delays at any stage can heavily undermine the real-time nature of the system. Handling frequent variations in video quality, lighting conditions, and diverse environments adds another layer of complexity, necessitating robust algorithms that are capable of adapting dynamically.
The development of a holistic software application for video analytics involves a complex processing pipeline with multiple steps. The processing pipeline can become even more intricate when multiple AI models are used for each video frame in a cascading fashion, such as a detection model followed by a classification model, or the output of a model to be the input of another model. For certain AI analysis tasks, it might be necessary to keep track of past output data and perform logical reasoning over multiple frames.
Thirdly, processing one video stream is not the only need of the hour, but a plethora of video streams that must be pristinely processed. Mitigating these two challenges is not solely adequate to fulfill the requirements from the field. But these are absolutely necessary and minimal conditions to deal with serving more than 100 video streams per GPU or NPU. Each NPU core should be used for multiple video streams, meaning that each video stream processing should consume the smallest possible part of NPU core and CPU core. And, therefore, one 64-core CPU server with multiple cards that is expected to serve up to 1,000 video streams can be a colossal challenge. Balancing or removing bottlenecks of CPU and NPU processing resources should also be capably handled to ensure that the system works with 24/7 stability and precision.
Finally, real-time video AI inferencing requires high-performance computing resources, which can be expensive to acquire and maintain. Accomplishing this objective results in high total cost of ownership (TCO), including both capital expenditure (Capex) and operating expenditure (Opex). Therefore, selecting the best-empowering and most-fortified AI hardware platform to optimize the Capex as initial investment and Opex such as utilities cost is also a big challenge to scale video analytics applications.
Overcoming these challenges requires a multidisciplinary approach, combining advancements in hardware, AI optimization, and adaptive machine learning techniques, diligently tailored for real-time video analysis.
Salient Solution with Unparalleled Benefits
Having understood the underlying, complicated difficulties that a resilient AI application has to emphatically overcome, GuardPro from VinAI is a unique, niche offering designed to help business to minimize their total cost of ownership. The system runs on the Qualcomm Cloud AI 100 platform and offers lightning processing speeds and efficiency of complex data, high reliability, simplified deployment, fortified security, and compelling cost-reductions. The statistics are significant when it comes to the optimizations in expenses realized with the system. Since May 2023, GuardPro has been successfully deployed in Vinhomes’ residential areas with a tremendous 35% saving in Capex compared with competitor’s solutions, and a significant 50% saving in Opex with estimated AI inference power consumption.
Deep Learning Model Latency & Power Consumption
The inference time is how long it takes for a forward propagation. Floating Point Operations (FLOPs) and Multiply-Accumulate Operations (MACs) are commonly used to calculate the computational complexity of deep learning models. MAC is an operation that does an addition and a multiplication. Two operations are involved, as a rule. One MAC equals roughly two FLOPs. The FLOPS, with a capital S denotes the Floating-Point Operations per Second; the more operations per second that the hardware can perform proficiently, the faster the inference will be. The inference time will be FLOPs/FLOPS. Inference time is also known as Latency. Inference speed is a metric used to measure latency (that is, Inferences per Second or Frames per Second). Given a DL model, FLOPs can be calculated. Therefore, Inference time can be calculated, based on a given hardware. Each inference also consumes power. AI inference acceleration cards often use Tera Operations Per Second (TOPS) to measure the processing ability of a hardware card. No specific rule is available to convert from TOPS to FLOPS because AI inference acceleration cards often accept different data types.
Deeper and larger DL model architectures are frequently used to solve complex problems; however, they also often do have higher Latency and consume more power. Meanwhile, real-time video analytics requires both Low Latency and Low Energy Consumption because anomaly detection should be detected as real-time. Meanwhile, running the system round-the-clock invariably requires enormous power. Deeper and larger DL models are increasing with time such as vision transformer backbone models.
The Qualcomm Cloud AI 100 platform, designed for AI inference acceleration, addresses unique requirements from edge to cloud, including perceptible power efficiency, solidified scalability, process node advancements, and synchronized signal processing, thereby, facilitating the ability of datacenters to run inference on the edge cloud faster and more efficiently. The standard card has 350 TOPS, while consuming only 75 watts of power and supporting data types of FP16, INT16, INT8, and FP32 [1]. Therefore, Qualcomm Cloud AI 100 for AI Inference is a great hardware choice for Real-time Video Analytics.
High Throughput
A substantial number of videos processed by AI in real-time with Edge solution is an essential demand because Capex is a significant concern, in conjunction with Opex that is a core consideration for calculating Return on Investment (RoI). To optimize processing throughput for high-volume video analytics applications, it is essential to offer a software library and reference designs including the following:
(1) A reference design for a software application that can effectively process video data from multiple camera streams
(2) A toolkit that enables the deployment of multiple applications on multiple cards to serve even multiple DL Models at the same time. These resources are instrumental in facilitating the development of end-to-end video analytics solutions that can handle large volumes of data with efficiency and accuracy. AI accelerator cards often provide AI development SDKs on top of hardware design. For example, Qualcomm Cloud AI 100 card provides two imperative SDKs:
- Cloud AI Apps SDK (compiler, simulator, sample codes)
- Cloud AI Platform SDK (runtime, firmware, kernel drivers, tools)
These SDKs strongly support AI solution developers, who can fully utilize the computational power of the card.
Production Optimization
Production optimization for real-time video analytics requires tight-coupling the following main factors into a promising product:
- High Accuracy
- Low Latency
- High Throughput
Low latency, while preserving high accuracy, requires expertise of AI optimization, in which AI models are selected. The carefully chosen AI model uses a cluster of individual optimization techniques such as pruning, quantization, and NAS, with all of these coherent techniques bundled into a cascaded design. High throughput can be achieved by optimizing full-pipeline video processing and using AI inference accelerator cards.
GuardPro for Vinhomes Smart City Projects
GuardPro is a Video Analytics product of VinAI that transforms ordinary IP cameras into a comprehensive security system. It enhances security, compliance, and convenience with unhindered 24/7 surveillance and replete real-time notifications. GuardPro uses foundational AI technologies such as face recognition, action recognition, people detection and tracking, vehicle detection, classification, and tracking, object detection and size estimation, automatic license plate recognition, crowd detection, size estimation, and flow tracking.
The prominent distinguishing factors that cause GuardPro to be a versatile solution, when compared with other real-time video analytics products in the market, are:
(1) GuardPro has achieved all-encompassing high accuracy, low latency, and high throughput. GuardPro is designed to combat the high costs driven by the massive computational resources needed for AI processing.
(2) Moreover, GuardPro is designed to support various CPU, NPU, GPU types. GuardPro Video Analytics platform can also be easily deployed to edge box, edge server, or on cloud. Therefore, it can serve from small to large scale number of cameras with optimized Capex for customers.
GuardPro has been commercialized for Vinhomes smart city projects, for which GuardPro has used Qualcomm Cloud AI 100-powered solution. It helps to lower hardware costs by 35%, when compared with the leading alternative solution and supports large-scale systems with thousands of camera streams, while remaining very cost-effective.
Qualcomm Cloud AI 100 platforms in production environments enable rich, replete, and rigorous inference capabilities. Such seamless and simplified interoperability of Qualcomm Cloud AI 100 with heterogenous vendor appliances makes it one of the most valuable and easily-usable solutions for seamless integration and deployment in a wide spectrum of scenarios.
Figure 1 illustrates the GuardPro software stack, which supports both CPU and Qualcomm Cloud AI 100 NPU. Figure 2 presents the GuardPro edge system architecture.
Figure 1. Guardpro Software Stack
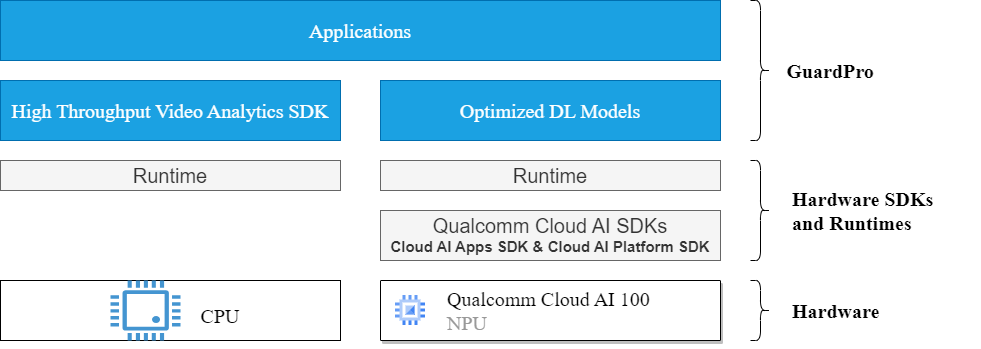
Figure 2. GuardPro System Architecture
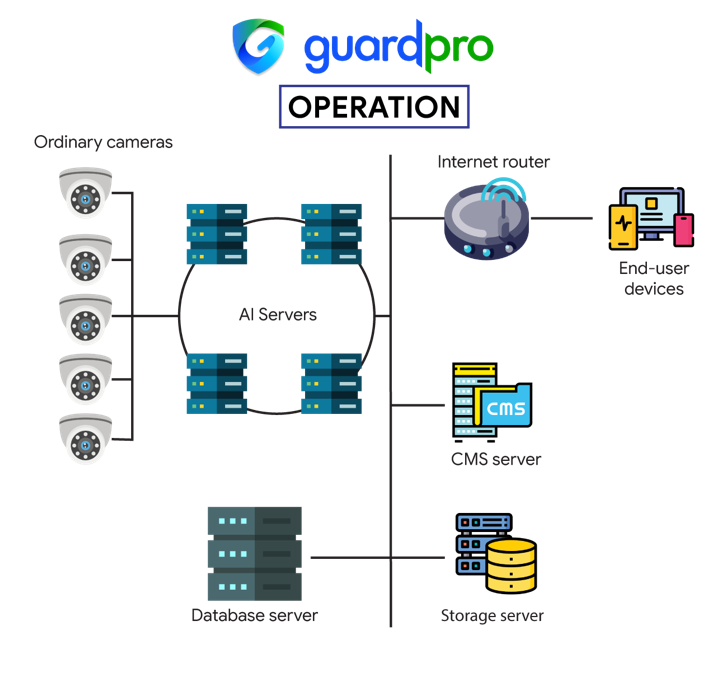
GuardPro is suitable for various business use cases, such as safety and security enhancement, compliance enhancement, and convenience enhancement. For instance, it can be used for access control based on face recognition, theft prevention based on license plate recognition, parking violation detection, fall and unconsciousness detection, and more such scenarios.
Case Study for Vinhomes Smart City Projects
GuardPro has been successfully deployed at three mega Vinhomes smart city projects including Vinhomes Smart City [2], Vinhomes Ocean Park in Hanoi, and Vinhomes Grand Park in Ho Chi Minh City, Vietnam.



Up to date, GuardPro has handled 10 AI features on more than 11,000 video streams for Vinhomes’ residential areas since May 2023 with the following phenomenal advantages:
- Saved 35% of hardware investment cost in Capex.
- Optimized Opex by saving over 50% of estimated AI inference power consumption.
Table 1 describes the hardware specifications that have been commercialized with GuardPro. The corresponding benchmarking results for all 10 AI features with a single Qualcomm Cloud AI 100 standard card to confirm the aforementioned remarkable advantages have been described in Table 2.
Table 1. Hardware specifications for GuardPro
| Hardware type | Main specifications |
| Server | AMD Barebone G292-Z43 HPC Server – 2U DP 16 x Gen4 GPU Server: – CPU: 2x Milan 7713 (Milan: 64C, 225W, 2.0G) – Memory: 16x DDR4 RDIMM ECC 3200MHz 16GB – HDD: 2x Seagate 600G 2.5″ SAS |
| NPU | Qualcomm AIC100 Standard Card – Form factor: PCIe HHHL (68.9mmx169.5mm) – Power (TDP): 75W – Peak Integer Ops (INT8): Up to 350 TOPS – Peak FP Ops (FP16): Up to 175 TFLOPS – DRAM (w/ ECC): 16 GB LPR4x – 137GB/S – Host Interface: PCIe Gen4, 8 lanes |
Table 2. Benchmarking results
| AI feature | Throughput | Precision and Recall | |
| Number of RTSP streams H265@10fps | fps | ||
| Blocklist detection (face recognition with far distance mounted camera) | 125 | 1250 | > 90% |
| Face recognition for access control (open door and control elevator) | 116 | 1160 | > 99% |
| Invalid parking | 152 | 1520 | > 90% |
| Automatic license plate recognition | |||
| Bulky items in the elevator | 161 | 1610 | > 85% |
| Items in the hallway | 185 | 1850 | > 85% |
| Unmask detection | 160 | 1600 | > 85% |
| Pet detection | 161 | 1610 | > 85% |
| Laying down | 121 | 1210 | > 85% |
| Harassment | 83 | 830 | > 70% |
For overall processing efficiency of a server, based on AI features planning for cameras of smart cities, each server can be installed with 5 or 6 cards of Qualcomm Cloud AI 100. As a result, each server can handle up to a thousand camera streams.
Reference
[1] https://www.qualcomm.com/products/technology/processors/cloud-artificial-intelligence/cloud-ai-100

It is a long established fact that you are reading content by Top 20 AI Research Company in the world.






